Trainees Edition
Trainers Edition
Trainees Edition
Trainers Edition
Module 6: The Age of Algorithms
Module Description
The main purpose of this Module is to raise awareness about algorithms, how they work and how they affect people and societies as well as the benefits and consequences of automated decision making.
The secondary aim is to guide trainers who want to use the content of this Module to train their trainees.
With these aims in this module, how algorithms work, their possible impact on people, societies and daily life, why they need to be approached and used by caution along with guidelines about how to teach the subject are covered.
Trainees who successfully complete this module will be able to:
- demonstrate an understanding of what algorithms are and how they work
- demonstrate an understanding of how algorithms affect people and societies
- demonstrate an understanding of pros and cons of algorithms
- demonstrate an understanding of the connection between algorithms, news and news feeds
- demonstrate an understanding of filter bubbles and echo chambers
Additionally, trainers who successfully complete this module, will be able to demonstrate an understanding of the guidelines for training on the subject.
Module Structure
This Module consists of the following parts:
- Module Description (objectives, description of the content and learning outcomes)
- Module Structure
- Guidelines for Trainees
- Guidelines for Trainers (how to get prepared, methods to use and tips for trainers)
- Content (study materials and exercises)
- Quiz
- Resources (references and recommended sources and videos)
Main objectives of the module, description of the content and the learning outcomes are explained in the Module Description part. Content includes all study materials and the content related exercises. Quiz includes multiple choice and true/false questions for trainees to test their progress. Resources have two components: references and recommended sources for further study. References is the list of resources cited in the content part. Recommended sources consist of a list of supplemental sources and videos which are highly recommended to read and watch for learning more on the topic. Guidelines for Trainees includes instructions and suggestions for trainees. Guidelines for Trainers leads trainers through different phases of the training and provides tips which could be useful while teaching the subject.
Guidelines for Trainees
Trainees are expected to read the text, closely study examples, watch recommended videos and do the exercises. They can consult suggested sources for further information. After completing the study of the content trainees are strongly suggested to take the quiz to evaluate their progress. They can revise the study material when and if needed.
Guidelines for Trainers
Guidelines for trainers includes suggestions and tips for trainers about how to use the content of this Module to train people on the algorithms, the potential they have to affect people, their decisions and societies.
Getting Prepared
Preparing a presentation (PowerPoint/Prezi/Canva) which is supported with some visual materials which displays the results of search engine searches by different people or from different locations is strongly suggested. Alternatively a real time demonstration can be planned.
Getting Started
A short quiz (3 to 5 questions) in Kahoot or questions with Mentimeter can be used at the beginning for engaging participants in the topic. It can be used as a motivation tool as well as a tool to check trainees’ existing knowledge about the subject.
Methods to Use
Various teaching methods can be used in combination during the training. Such as:
- Lecturing
- Discussion
- Group work
- Self reflection
Tips for Trainers
Warming-up
An effective way of involving participants and setting common expectations about what they will learn is to ask a few preliminary questions on the subject. This can be done through group work by asking trainees to discuss and collect ideas, but also individually by asking each participant to write their ideas on sticky notes.
The activity can be conducted as follows:
- Ask trainees what they think about the place of algorithms in their daily life
- Ask trainees to classify the given examples and make a list of places/circumstances decisions are taken by algorithm
- Ask trainees whether algorithms have anything to do with the news we are exposed
- Ask trainees who writes this algorithms and sets the decision making rules/parametresAfter the discussions, making sure that trainees are able to understand algorithms are everywhere in our daily lives and they are written by other people and have a potential for manipulation.
Presenting the Objective of the Lesson
The objective of the lesson should be made clear (which is to raise awareness about algorithms, their place in daily life and their potential for manipulation). Following the warming-up question it will be easier to clarify the objectives.
Presenting the Lesson Content
While presenting the content make sure to interact with the trainees and encourage them for active participation.
- Before providing a definition of algorithm, ask participants to define it elaborate on its functions.
- Before providing an overview of the benefits and potential risks of algorithms, ask participants to elaborate on it.
- When talking about the differing results for the same search (by different people or location) from search engines, either support your claim with screen shuts or make a real time demonstration
- If time and facilities allow, ask participants to perform the same search and compare results.
- Make the connection between algorithms and news/news feeds clear
- After completing a comprehensive overview of the algorithms, filter bubbles and echo chambers, ask participants to elaborate on the role algorithms play in the spread of misinformation.
Concluding
Make a short summary of the lesson and ask a couple of questions which underline the most important messages you planned to give.
- Ask trainees whether being aware of the algorithms helps them to take control.
After the discussions make sure that trainees understand that algorithms are making decisions for us and there is a room for manipulation.
Content: The Age of Algorithms
Introduction
Algorithm is the set of instructions and rules used by computers on a body of data to solve a problem, or to execute a task (Head, Fister & MacMillan, 2020, p. 49). An algorithm can be seen as a mini instruction manual telling computers how to complete a given task or manipulate given data (What is an algorithm?, n.d.).
Algorithms curate content by prioritising, classifying, associating, and filtering information. Prioritisation ranks content to bring attention to one thing at the expense of another. Classification involves categorising a particular entity as a constituent of a given class by looking at any number of that entity’s features. Association marks relationships between entities. And filtering involves the inclusion or exclusion of certain information based on a set of criteria (Diakopoulos, 2013, p. 4-8).
Filtering algorithms often take prioritisation, classification, and association decisions into account. For instance, in news personalization apps, news is filtered according to how that news has been categorised, how it has been associated to the person’s interests, and how it has been prioritised for that person. Based on filtering decisions certain information is over-emphasized while others are censored (Diakopoulos, 2013, p. 4-8).
The rise of the “age of algorithms” has had a profound impact on society, on politics, and on the news. Algorithms are powerful, efficient and often questionable drivers of innovation and social change (Head, Fister & MacMillan, 2020, p. 4). Today, increasingly sophisticated algorithms are being designed to aid and sometimes completely replace human intervention in decision-making tasks. They seem to do it all at a lower cost and improved efficiency than human effort (O’Neil, 2016). The potential benefits of automated decision-making are myriad and clear, and yet at the same time, there are some risks and concerns involved (Olhede & Wolfe, 2019, p. 2).
The large-scale availability of data, coupled with rapid technological advances in algorithms, is changing society markedly (Olhede & Wolfe, 2019, p. 2). In daily life, algorithms are often used to sway decisions about what people watch, what they buy (Head, Fister & MacMillan, 2020, p. 5) and even how they vote (Epstein & Robertson, 2015). Algorithms filter search results from search engines. They may be programmed to decide who is invited to a job interview and, ultimately, who gets a job offer. They can be used for managing social services like welfare and public safety.They might recommend which loan applicants are a good credit risk. These invisible lines of code can make medical diagnoses and may even establish the length of a criminal sentence (Head, Fister & MacMillan, 2020, p. 4-5).
Algorithms make impactful decisions that can and do amplify the power of businesses and governments (Diakopoulos, 2013, p. 29). While making decisions, algorithms might promote political, economic, geographic, racial, or other discrimination, for instance, in health care, credit scoring and stock trading (Pasquale, 2011). Algorithms exert power to shape the users’ experience and even their perception of the world (Diakopoulos, 2013, p. 3). Despite the fact that their operations might sometimes cause injustice and can shape people’s perceptions and affect their choices, people are often unaware of their presence because they are invisible.
Algorithmic power isn’t necessarily detrimental to people, it can also act as a positive force (Diakopoulos, 2013, p. 2). Algorithms, in fact, are not inherently good or bad. Rather, their effects depend on what they are programmed to do, who’s doing the programming, how the algorithms operate in practice, how users interact with them, and what is done with the huge amount of personal data they feed on (Head, Fister & MacMillan, 2020, p. 4). However, it is important to recognize that they operate with biases and they can make mistakes. The lack of clarity about how algorithms exercise their power over people is the problem. Algorithmic codes are opaque (not transparent) and hidden behind layers of technical complexity (Diakopoulos, 2013, p. 2).
Their effects are important (Barocas, Hood & Ziewitz, 2013; Hamilton, Karahalios, Sandvig & Eslami, 2014; Sandvig, Hamilton, Karahalios & Langbort, 2014). For example, search algorithms structure the online information available to a society, and may function as a gatekeeper (Granka, 2010, p. 364-365; Introna & Nissenbaum, 2000). The search results a Web search engine provides to its users have an outsized impact on the way each user views the Web (Xing, Meng, Doozan, Feamster, Lee & Snoeren, 2014). Researchers tested the effect of personalised search results on Google, and found that results differ based on several factors such as Web content at any given time, the region from which a search is performed, recent search history, and how much search engine manipulation has occurred to favour a given result (Xing , Meng, Doozan, Feamster, Lee & Snoeren, 2014).
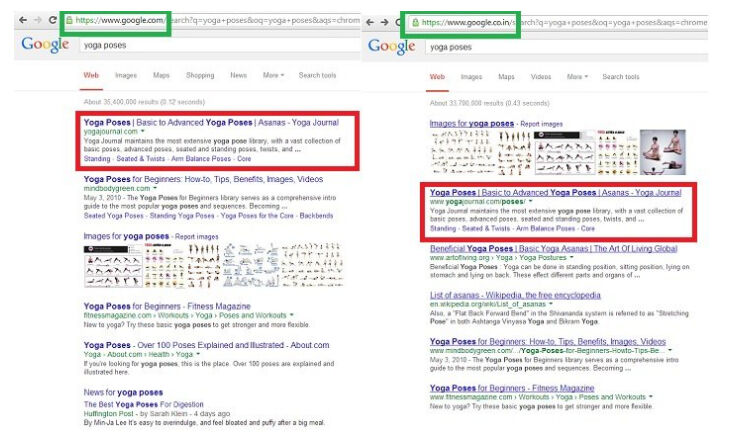
Source: Gohel, 2013
Research has demonstrated that the rankings of search results provided by search engine companies have a dramatic impact on consumer attitudes, preferences, and behaviour. Internet search rankings have a significant impact on consumer choices, mainly because users trust and choose higher-ranked results more than lower-ranked results. Given the apparent power of search rankings, researchers investigated whether they could be manipulated to alter the preferences of undecided voters in democratic elections. Findings show that biassed search rankings can shift the voting preferences of undecided voters by 20% or more, the shift can be much higher in some demographic groups, and such rankings can be masked so that people show no awareness of the manipulation (Epstein & Robertson, 2015).
There is a widely held misconception of algorithms (as mathematical models) and their results being fair, objective and unbiased (O’Neil, 2016). Because algorithms are processed by computers and follow logical instructions, people often think of them as neutral or value-free, but the decisions made by humans as they design and tweak an algorithm and the data on which an algorithm is trained can introduce human biases that can be compounded at scale (Head, Fister & MacMillan, 2020, p. 49). Algorithms also take poor proxies to abstract human behaviour and churn out results. The use of poor proxies to measure and abstract reality can often be discriminative in nature. Algorithms make decisions without having to explain how they arrived at them (O’Neil, 2016). On the contrary, in the case of a human decision maker, there is a feedback loop which allows for correction of errors in judgement (O’Neil, 2016). Moreover, the algorithms that social sites use to promote content don’t evaluate the validity of the content, which can and has spread misinformation (Jolly, 2014).
As a conclusion it can be said that algorithms are here to stay but they need to be used with caution (O’Neil, 2016).
Life in the Age of Algorithms: The Big Picture
The world of information has been transformed in unexpected ways in the past decade. These changes can be explained, in part, by the impact of algorithms. Some of the factors driving these changes help us to see the big picture which is summarised by Head, Fister and MacMillan, (2020, p. 5-7) as follows:
- Data collection about our daily lives is happening invisibly and constantly.
- Advances in data science allow systems to collect and process data in real time, rapidly and on a vast scale (“big data”).
- Data collected from numerous sources is quickly correlated.
- Automated decision-making systems are being applied to social institutions and processes that determine things such as who gets a job, a mortgage, or a loan, access to social services, admission to school or educational services.
- Machine learning and artificial intelligence, increasingly used in software products that make very significant decisions, often rely on biassed or incomplete data sets.
- The disaggregation of published information and its redistribution through search and social media platforms makes evaluation of what used to be distinct sources (e.g. scholarly articles, newspaper stories) more difficult.
- Profitable industries gather data from people’s interaction with computers to personalise results, predict and drive behaviour, target advertising, political persuasion, and social behaviour at a large scale.
- These industries appear to have difficulty anticipating or responding to unintended consequences.
- The rise of social media platforms which have no code of ethics contributes to distrust of established knowledge traditions such as journalism and scholarship.
- The technical infrastructure that influences how people acquire information and shapes their knowledge and beliefs are largely invisible, by design, to the public.
- There is a lack of public knowledge about who holds power over information systems as well as their algorithms and how that power is wielded.
Consequently, understanding how information works in the age of algorithms, is of paramount importance for individuals (Head, Fister & MacMillan, 2020, p. 7-8).
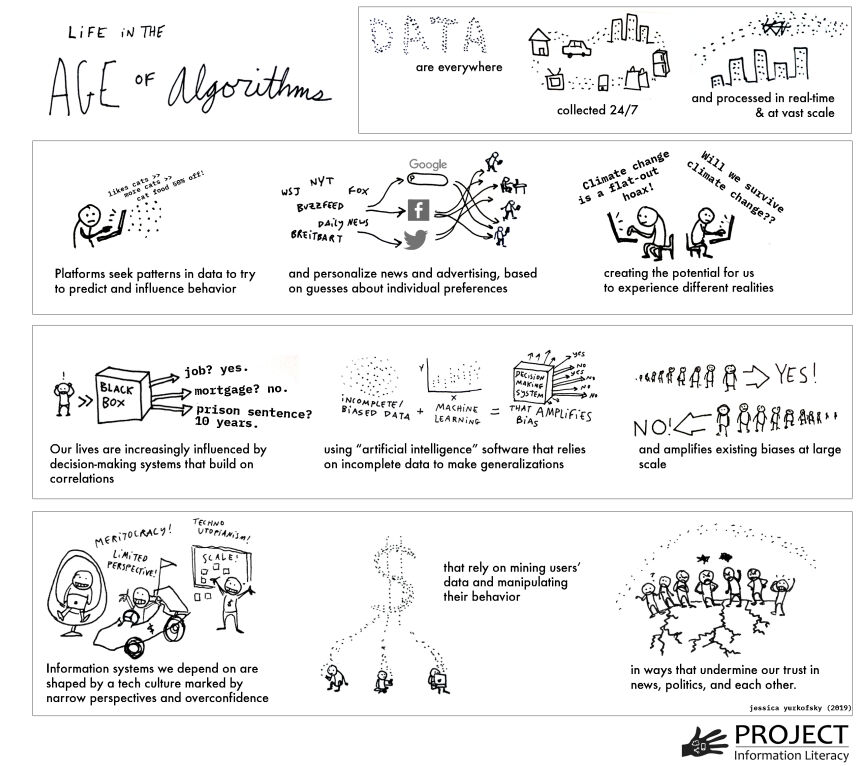
Source: Head, Fister & MacMillan, 2020, p. 6.
News, News Feeds and Algorithms
Among other things, algorithms are also often used to filter the news we see about the world. Today, readers are increasingly discovering news through social media, email, and reading apps, therefore homepage traffic for news sites continues to decrease. Publishers are well aware of this, and have tweaked their infrastructure accordingly, building algorithms that change the site experience depending on where a reader enters from. As a result, people very likely see different front pages of newspapers online because they are customised for individuals. While publishers view optimising sites for the reading and sharing preferences of specific online audiences as a good thing, because it gets users to content they are likely to care about quickly and efficiently, that kind of catering may not be good for readers (Jolly, 2014).
News feeds, which provide users with frequently updated news, are another application where algorithms play an influential role. For example Facebook News Feed displays an algorithmically curated or filtered list of stories selected from a pool of all stories created by one’s network of friends (Eslami, Rickman, Vaccaro, Aleyasen, Vuong, Karahalios, Hamilton & Sandvig, 2015, p. 153). A research conducted on Facebook users to examine their perceptions of the Facebook News Feed curation algorithm showed that more than half of the participants (62.5%) were not aware of the News Feed curation algorithm’s existence at all. They believed that every single story from their friends and pages they follow had appeared in their News Feed (Eslami, Rickman, Vaccaro, Aleyasen, Vuong, Karahalios, Hamilton & Sandvig, 2015, p. 153).

Algorithms make it much easier not just for people to find the content that they’re interested in, but for the content to find them that the algorithm thinks they’re interested in. Diakopoulos (2013, p. 2) claims that today algorithms, driven by vast troves of data, are the new power brokers in society.
Filter Bubbles
Filter Bubble is the intellectual isolation that occurs as a result of personalisation which facilitates avoiding exposure to information that conflicts with prior knowledge and opinions. It is the result of the curation of the user related information (such as browsing and search history, location, as well as social media feeds). Social media can easily encapsulate users into filter bubbles with the algorithms they use. While filter bubbles surround users with like-minded people who disseminate information that is aligned with their existing beliefs and opinions, they can cause less contact with people who have contradicting viewpoints. Personalised search results from Google and personalised news streams from Facebook are two examples to give for this phenomenon (Filter bubble, 2018; Cooke, 2018).
According to Pariser, who coined the term, filter bubble is the world created by the shift from “human gatekeepers,” such as newspaper editors who curate importance by what makes the front page, to the algorithmic ones employed by Facebook and Google, which present the content they believe a user is most likely to click on (Fitts, n.d.). The technology companies are commercial entities, and therefore to keep their shareholders happy need to encourage users to stay on their site for as long as possible to maximise the number of exposures to advertisements. They do so by tweaking the algorithms to deliver more of what users have liked, shared or commented on in the past (Wardle & Derakhshan, 2017, p.52). This new digital universe is “a cosy place, populated by the user’s favourite people and things and ideas.” (Fitts, n.d.). However, this selective exposure of information causes concern not only because of its cognitive aspects but also moral, political, and social aspects (Cisek & Krakowska, 2018).

There is no doubt that personalization helps fight against information chaos and information overload by facilitating access to relevant, useful information and avoiding the rest (irrelevant, not useful, irritating, etc.). However, there is an important difference between self-selected personalization and preselected personalization. In preselected personalization algorithms choose the content for users while in self-selected personalization people choose and decide which content they want to see. Obviously this is not something new. People have always (and still are) experienced filter bubbles because there were/are always information gatekeepers (such as parents, governments, religions, social groups) however, there are serious concerns when these bubbles are invisible and involuntary. When people do not know that information they get is personalised, they may assume that it is complete and objective. Algorithms as gatekeepers (in other words censorship mechanisms) can hinder access to content as well as awareness that there are other viewpoints. Worst of all, they are not based on ethical principles (Cisek & Krakowska, 2018). The value of the filters cannot be denied, however, the potential they possess in leaving people blind to ideas or events is quite alarming (Anderson, 2016).
Negative aspects of filter bubbles are summarised as follows by Cisek and Krakowska (2018): “Creating a misleading and erroneous image of reality, an individual mental model; closure in a limited, hermetic circle of information, opinions, views, worldviews, limiting the acquisition of knowledge; confirmation bias and cognitive bias formation; promoting intellectual and emotional laziness”.
Bursting filter bubbles is possible, first of all, by realising that filter bubbles exist, and then developing critical thinking and news literacy skills. Cisek and Krakowska (2018) make the following suggestions to burst filter bubbles: Seeking for information actively rather than passively consuming what algorithms have chosen; using the benefits of advanced search tools offered by search engines (the Boolean operators, commands, phrase, advanced search, etc.); using various search engines and comparing results; using search engines that do not track users and do not personalise (such as DuckDuckGo, Qwant, StartPage); using software that helps to get out of the filter bubbles (such as Escape Your Bubble, FleepFeed, Pop Your Bubble) and also keeping in mind that there is the Deep Web.
According to Wardle and Derakhshan (2017) “the ultimate challenge of filter bubbles is re-training our brains” and training people “to seek out alternative viewpoints”. Because, if/when we recognise that people seek out and consume content for many reasons beyond simply becoming informed, like feeling connected to similar people or affiliating with a specific identity, it means that pricking the filter bubbles requires more than simply providing diverse information.
Echo Chambers
Echo chamber, in news media, is a metaphorical description of a situation in which beliefs are amplified by repetitive communication inside a closed system. In an echo chamber, people confront information which reinforces their existing beliefs and views. This can be seen as an unconscious exercise of confirmation bias which may increase political and social polarisation and extremism (Echo chamber, 2020).
Echo chambers and filter bubbles are two close concepts which are generally used interchangeably. However, “echo chamber refers to the overall phenomenon by which individuals are exposed only to information from like-minded individuals, while filter bubbles are a result of algorithms that choose content based on previous online behaviour” (Echo chamber, 2020). In other words, filter bubbles contribute to the creation of echo chambers which certainly have political and social consequences.

"crop circle - echoes" by oddsock is licensed under CC BY 2.0
Echo chambers provide safe spaces for sharing beliefs and worldviews with others, with little fear of confrontation or division (Wardle & Derakhshan, 2017). Agents who are creating disinformation target groups inside echo chambers, “that they know are more likely to be receptive to the message” and there will be “no one to challenge the ideas. It is very likely that the message will then be shared by the initial recipient” (Wardle & Derakhshan, 2017). “As research shows, people are much more likely to trust a message coming from someone they know” (Metzger, Flanagin & Medders, 2010). This is why disinformation can be disseminated so quickly. It is travelling between peer-to-peer networks where trust tends to be high. The fundamental problem is that filter bubbles worsen polarisation by allowing people to live in their own online echo chambers and leaving them only with opinions that validate, rather than challenge, their own ideas (Wardle & Derakhshan, 2017).
Repetition theory lies behind both phenomena and it is what makes fake news work, as researchers at Central Washington University pointed out in a 2012 study. A psychologist, Lynn Hasher, from the University of Toronto claims that "repetition makes things seem more plausible," "and the effect is likely more powerful when people are tired or distracted by other information" (Dreyfuss, 2017).
Exercise
Exercise 1
Exercise 2
Quiz
References
Anderson, T. (2016). Is Google Scholar a filter bubble?
Barocas, S., Hood, S., & Ziewitz, M. (2013). Governing algorithms: A provocation piece. In Governing Algorithms: A Conference on Computation, Automation, and Control.
Cisek, S. & Krakowska, M. (2018). The filter bubble: a perspective for information behaviour research. Paper presented at ISIC 2018 Conference.
Cooke, N. (2018). Fake news and alternative facts: Information literacy in a post-truth era. ALA.
Diakopoulos, N. (2013). Algorithmic Accountability Reporting: On the Investigation of Black Boxes. Tow Center for Digital Journalism.
Dreyfuss, E. (2017). Want to make a lie seem true? Say it again. And again. And again. Wired.
Echo chamber (media). (2020). In Wikipedia.
Epstein, R. & Robertson, R. E. (2015). The search engine manipulation effect (SEME) and its possible impact on the outcomes of elections. In: Proceedings of the National Academy of Sciences 112 (33), E4512-E4521.
Eslami, M., Rickman, A.,Vaccaro, K., Aleyasen, A.,Vuong, A., Karahalios, K., Hamilton, K. & Sandvig, C. (2015). "I always assumed that I wasn't really that close to [her]": Reasoning about Invisible Algorithms in News Feeds. In: CHI '15: Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (pp. 153–162).
Filter bubble. (2018). In Technopedia.
Fitts, A. S. (n.d.). The king of content: How Upworthy aims to alter the Web, and could end up altering the world. Columbia Journalism Review.
Gohel, J. (2013). Google shows different UI in India and US.
Granka, L. A. (2010). The Politics of Search: A Decade Retrospective. The Information Society, 26(5), 364–374.
Hamilton, K., Karahalios, K., Sandvig, C., & Eslami, M. (2014). A path to understanding the effects of algorithm awareness. In Proc. CHI EA 2014, ACM Press (2014), 631–642.
Head, A.J., Fister, B. & MacMillan, M. (2020). Information literacy in the age of algorithms: Student experiences with news and information, and the need for change. Project Information Research Institute.
Introna, L., & Nissenbaum, H. (2000). Shaping the Web: Why the Politics of Search Engines Matters. The Information Society, 16 (3), 169-185.
Jolly, J. (20 May 2014). How algorithms decide the news you see: Past clicks affect future ones. Columbia Journalism Review.
Khorev, M. (2016). Why do different browsers and devices show different search results on Google?
Metzger, M.J., Flanagin, A.J. & Medders, R.B. (2010) Social and Heuristic Approaches to Credibility Evaluation Online. Journal of Communication, 60(3), 413-439.
O’Neil, C. (2016). Weapons of math destruction: How big data increases inequality and threatens democracy. Crown Publishers.
Olhede, S.C. & Wolfe, P. J. (2019). The growing ubiquity of algorithms in society: Implication, impact and innovation. Philosophical Transactions of the Royal Society, 376 (128).
Pariser, E. (2011). The Filter bubble: How the new personalized Web is changing what we read and how we think. Penguin Books.
Pasquale, F. A. (2011). Restoring Transparency to Automated Authority. Journal on Telecommunications and High Technology Law, 9(235).
Sandvig, C., Hamilton, K., Karahalios, K., and Langbort, C. (2014). Auditing algorithms: Research methods for detecting discrimination on internet platforms. In Data Discrimination: Converting Critical Concerns into Productive Inquiry.
Wardle, C. & Derakhshan (2017). Information disorder: Toward an interdisciplinary framework for research and policymaking. The Council of Europe.
What is an algorithm? An ‘in a nutshell’ explanation. (n.d.). Think Automation.
Xing X., Meng W., Doozan D., Feamster N., Lee W. & Snoeren A.C. (2014). Exposing Inconsistent Web Search Results with Bobble. In: Faloutsos M., Kuzmanovic A. (eds) Passive and Active Measurement. PAM 2014. Lecture Notes in Computer Science, vol 8362. Springer, Cham.
Recommended Sources
Cooke, N. (2018). Fake news and alternative facts: Information literacy in a post-truth era. ALA.
Diakopoulos, N. (2013). Algorithmic Accountability Reporting: On the Investigation of Black Boxes. Tow Center for Digital Journalism.
Recommended Videos
Khorev, M. (2017). Why are my search results different than others’ search results?
Praiser, E. (2018). How news feed algorithms superchange confirmation bias. Big Think.
GCFLearnFree.org. (2018). How filter bubbles isolate you.
GCFLearnFree.org. (2019). What is an echo chamber?